
Elad Gil's Co-Pilot for Next Gen. Data Stack
And why the stuff You know, or you think you know, is NOT what this is all about...

So a few months ago Elad Gil solicited pitches around this idea of generating SQL from Text prompts:

I love seeing the flood of twitter responses to Elad’s post. Some tools add an interactive conversational interface to their existing BI. Others embed SQL generators into collaboration software such as Slack. The big variety of solutions shows you just how multi-dimensional this space is - as opposed to something as generic and straight forward as, say, Data Observability - which we could not stop hearing about during the last few years, but which largely failed to deliver anything of significance.
In short, the post has all the signals of a new category in the making. So let’s talk about what this category actually is and is not.
SQL Generators are NOT New
First, it is important to highlight that relying on machines to generate SQL is an old idea, at the center of the basic BI experience. BI tools going as far back as MicroStrategy of the 1990s relied on some form of data modeling to describe the underlying database schema and the relationships within its entities.
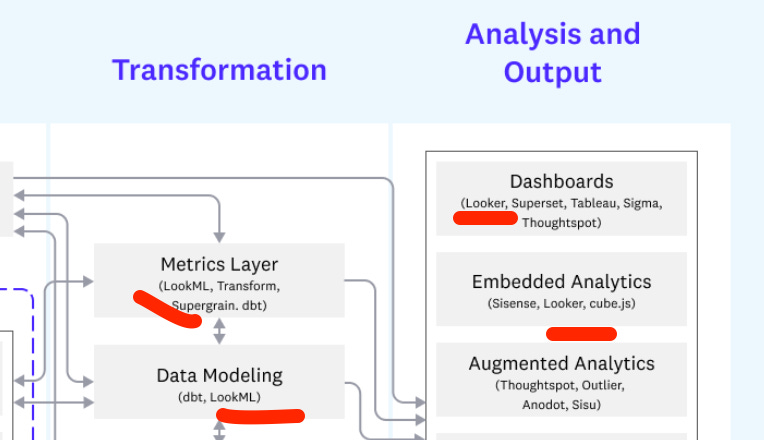
The reason we need data modeling is because it helps machines understand data through the human eyes.
The reason we need data modeling is because it helps machines understand data through the human eyes.
At Looker we invented an entire modeling language, called LookML, to improve Analyst’s ability to model data, and software’s ability to generate SQL against the database. We did not need AI to generate SQL.
Interactive Experiences are Not New
If you’ve read me before, or we talked, you know I am passionate about things in Elad’s slide - specifically data modeling tooks like DBT. I think it is one of the most misunderstood aspects of the Modern Data Stack. It is also one in which, in my opinion, we can have major impact:
But the thing I am completely NOT excited about is yet another interactive experience. Yet, this is apparently the first thing that largely comes to everyone’s mind today.
A text-to-SQL interface for a Business User is not the thing anyone should be striving for. Replacing Analysts with ChatGPT is an attractive idea, but it won’t work in practice. Benn Stancil put it best:
The demos run in small sandboxes that don’t resemble real data environments. The test questions are basic, unambiguous, and could be answered by an experienced analyst in a handful of lines of SQL. The distance between current AI start-ups focusing on Data and companies’ actual data ecosystems is staggering. Tristan Handy, the CEO of dbt Labs’, said that a meaningful percentage of their customers are using dbt to create more than 5,000 tables. In that environment, there are no simple questions—answering “How many new European accounts did we add last week?” requires defining an account, what new means, where Europe is, when a week starts, in what time zone it should be calculated in, and if “add” means net or gross.
Instead, what’s needed is an AI junior data developer. An AI that doesn't just generate a codebase, but produces that initial draft and then offers an interactive environment where users—maybe other developers—can give feedback. The AI that refines the codebase based on this feedback, bridging the gap between the imagined concept and a testable product.
AI for Data Infrastructure
Currently, there are an estimated 1 billion Excel users worldwide, with 120 million in the USA alone. By contrast, each of the top BI tools (PowerBI, Tableau) barely tops 10 million world-wide. The challenge in more widespread adoption reflects the underlying complexity in bringing Excel-like capabilities for data manipulation to the world of business. Business use of BI tooling is still largely a multiplier on the number of people who can write complex data engineering code to power those end-user systems.
Business use of BI tooling is still largely a multiplier on the number of people who can write complex data engineering code to power those end-user systems.
The power of AI is not so much that we need new AI interfaces to speak to a BI tool—we can’t even get what we want when we speak to a Data Analyst—it is that we have the potential to go from just 50,000 analytics engineers to 20 million “modelers”, with AI simplifying tasks below the hood.
And if we go beyond Analytics Engineering, the potential is for 300 million users to treat advanced BI tools as nothing more than a personal Excel spreadsheet.
The Data App Future
Another related issue is what will the future BI even look like. Historically, we’ve been focused on internally-facing dashboards and reports. But this does not have to be the future.
One of the active developments within the data space has been the emergence of what is often called Data Applications. Unlike the traditional internally-facing enterprise scale Business Intelligence, data applications are more modular and can be both internally and externally facing. As companies accumulate large volumes of data, there emerges a new opportunity to create business applications on top of their existing data - for instance, Yelp could sell its data to restaurants for market analytics.
Yelp could sell its data to restaurants for market analytics.
Keep reading with a 7-day free trial
Subscribe to Mir's .Report to keep reading this post and get 7 days of free access to the full post archives.