
The new Standard for LLM Benchmarking
Ignore at your own risk when building Text-2-SQL applications

The previous week I did not write this newsletter. I was quietly working on a new benchmarking methodology/system/tool. The results are finally in (llmsql.streamlit.app), and are shared below 👇🏽.
Some of you might recall that back in February I wrote this review of Analytics tools incorporating new AI-dependent workflows for generating SQL and the overall takeaway was that they are quite bad.
Being the Data geek that I am, I set out on a deeper journey to quantify just how bad the whole Text-2-SQL AI is - not just the Business Intelligence packaging of it, but also the underlying foundational models. And the gap is BIG.
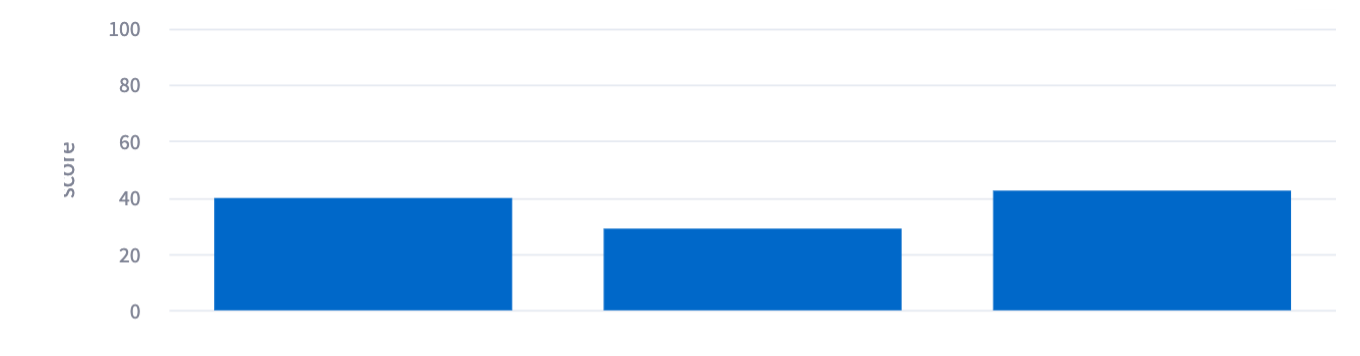
My conclusion: Your answers are going to be at least 1/2 bad regardless of the AI you use, but no one can predict which 1/2.
Implications for Code Generation and AI start-ups
The skeptics are welcome to skip to the methodology section, but I first want to illustrate what all of this actually means.
Today, in Silicon Valley, it is easy to overhear the following statements (Not the Author’s opinions):
RAG, fine-tuning, etc - none of that really matters since pretty soon you can just send everything in one context window, which are getting very big
Lag times - don’t worry about any of that. OpenAI, Anthropic, etc - they will fix speed issues
Hallucination - just set the temperature to 0. The models are getting so good, this will soon be a non-issue
Well, I am here to say that this is not quite the case.
You see, the above arguments might make very reasonable sense in relation to fixed tasks and problems: like summarizing a book. There is only that much improvement you can make to get a good quality summarization of some book. A summary can be written with a certain artistic flavor, but ultimately it is a task that does have a ceiling in terms of overall usefulness.
But code - well, ability to write code is an infinite problem. You can always benefit from the model having ability to write more and more accurate code.
According to my research, no model was accurate on more than 50% questions (~20-40% was the range for most). Great, you say. Next year we will have 2x better models, so they will have 100% accuracy. No, they won’t! Next year, improvement in technology will allow me to introduce at least 2x more complexity into my benchmarking dataset for the same amount of time and resources, likely lowering the performance of these models further by 2x, so the end results will be similar.
code generation is inherently a relative problem
This is because code generation is inherently a relative problem. No one today cares much whether ChatGPT can write more code than the average programmer from the 1980s. What matters is whether ChatGPT can replace a modern-era engineer, data analyst, etc. And if we take me as a benchmark for the level of an average Data Analyst, the answer is resounding: No - raw foundational models are not enough by themselves to replace the human coder.
The case for fine-tuning
Since anyone can now submit their own tests into my Streamlit App, I decided not to publish results of my benchmarking for various private start-ups - including a bunch from the last few YC cohorts (spoiler: they were NOT very good). But I do want to make a bigger point:
the future of code generation lies in fine-tuning for application-specific use cases
At this point I could just say: Trust me Bro. (Seriously, I and Data go back awhile. You should trust me!). But we’re all skeptics here, so let’s spell it out:
What is Benchmarking? Benchmarking is essentially a dataset that the tester (in this case me) built with some assumptions about the range of problems the models should be capable of solving.
What is fine-tuning? Fine-tuning is essentially a dataset that the engineer built with some assumptions about the range of problems the models should be capable of solving.
Notice any similarity? My point exactly!
Basically, while code generation at the foundational level is a very difficult problem, code generation for an enterprise use case is a solvable problem - though it can still be difficult.
The reason for this is actually quite simple. Foundational models are too generic for vendors to get good at. A specialized human is always going to be several steps ahead.
However, an enterprise application - even if it is an enterprise application for coding - can be narrowed just enough to allow someone with enough rigor and focus to make the training datasets required for the models to get good at the specialized use cases.
Motivation and Methodology
Ever since I started publishing on this topic of Text-2-SQL, I’ve come across countless start-ups that, if you did not know any better, made you believe that they have figured out the magic - that they could generate production-ready SQL.
But as someone who knows thousands of Data analysts, I was puzzled that actually very few people in my network relied on any of these new products. If all this tech works so well - how come no one I know seriously uses it?
Having looked at the existing methodology for benchmarks, I had the answer. The benchmarks are extremely simple - relying on very basic “one-dimensional” queries.
So I set out to build one that would mask lots of complexity behind seemingly simple questions.
For instance, a question such as “What is the average commission earned per store for each affiliate program?” seems simple enough until you realize that a simple way to pull an average will be an incorrect way (i.e. it causes a fanout).
Another simple question, “What is the total transaction revenue for each category in the store, where transaction revenue is calculated as the commission value multiplied by the order total?”, creates multiple theoretical solutions, but causes most to fail because of a trivial real-life scenario: part of the data is missing - just in the place it would normally be missing: a table reliant on human entry.
In other cases, I introduced bad data:
Q: Can you provide a list of customers who have valid email addresses as per the standard email address format?
GTP4 answer:
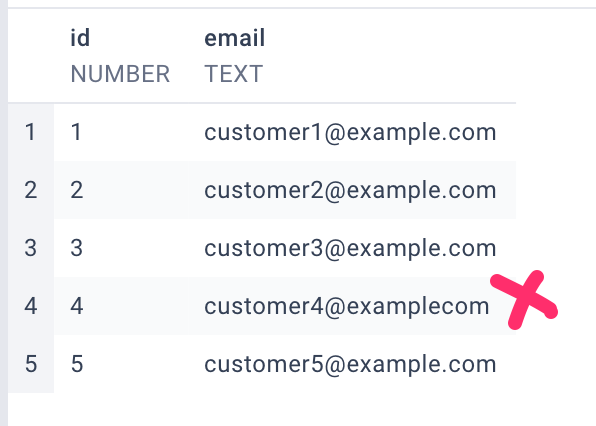
On and on, I have worked through the creation of ~200 such questions and related datasets.
I have tested all foundational models at the minimum temperature, with minimal necessary instructions (like the Database schema, etc). Every model was tested with several permutations - with the best results featured in the remaining upload. For each model, I estimate my results in absolute terms have the confidence range of +/- 5%. The reason for the wide range are multiple: evidence shows that instructions in the prompts actually do matter, so in theory it is possible to optimize prompts specifically to one model in such a way that the results would be better (I’ve used the same prompts for all of my testing).
Last but not least
At this point, the question everyone who has read all the way to this point should be asking is: will this be maintained? My answer: Yes!
The hackers might find a way to beat the benchmark. I openly invite all such attempts. My company’s internal tools allow us to easily label and review test results, diffs, etc - everything to help identify false patterns and devise new tests and questions. Here are some examples:


Bring Your Models! Bring It On! 🥷
-SG